The backend nobody wanted to build
Direct integration is reasonable when one protocol covers your product. After that, it becomes a maintenance commitment: historical data, position tracking, governance changes, per-vault wiring. The backend nobody wanted to build.

Most DeFi integrations do not fail at the deposit button. They fail in the backend nobody wanted to build.
If your product covers one protocol on one chain, direct integration can be reasonable. The major lending protocols have real integrator surfaces, and a good engineering team can ship a narrow action flow.
This post is about what happens after that. Three things in particular:
- The live action is only one part of the product. A production integration also needs historical data, utilization charts, transaction history, position tracking, account state, risk data, and support tooling.
- The long tail is not standardized. Vaults, curator products, lending markets, and newer chains each bring their own contract layout, share-price semantics, withdrawal mechanics, and governance cadence.
- The integration tax compounds. Every protocol and chain adds another address book, indexer, RPC read path, transaction builder, and QA surface.
vaults.fyi turns 80+ protocols across 20+ chains into one standard API and SDK surface. The custody boundary does not move. vaults.fyi never holds keys, never custodies funds, and never broadcasts transactions. We return unsigned transaction objects. The partner reviews, signs, and executes through its own wallet or infrastructure.
Where the gaps show up
Direct integration usually looks cleanest at the action layer. The product surface around the action is where the cost shows up.
Historical data for charts and analytics
Current rates and current balances are not enough for a production product. Market pages need APY history, utilization history, parameter history, transaction history, and sometimes share-price history. Those usually come from a mix of subgraphs, protocol APIs, direct contract reads, and your own joins.
Subgraphs are useful for historical charts and broad indexing. They are not real-time infrastructure. The Graph's own Uniswap subgraph postmortem documented hours of halted indexing under load, and Chaos Labs has published analysis of inconsistencies between Aave v3 subgraph responses and direct onchain reads.
For a historical chart, occasional indexer lag is annoying. For a borrow button, liquidation warning, collateral toggle, or available-borrow number, stale data can produce failed transactions or unsafe UI.
/v2/detailed-vaults
/v2/historical/{network}/{vaultId}
/alpha/borrow/markets/historical/{network}/{marketId}/{assetAddress}
Position tracking across products
A wallet view that answers "what does this user hold across Aave, Morpho, Veda, Ethena, Euler, Fluid, and curator products" is a stitching problem per protocol per chain.
Every product has its own position shape:
- Share-price or exchange-rate semantics
- Reward accrual model
- Pending withdrawal state
- Historical-value pipeline
- Asset and decimal normalization
- Chain-specific address registry
Protocol-specific SDKs can give you a strong position view for their own protocol. They do not give you the aggregated, normalized wallet view across the rest of the user's portfolio.
/v2/portfolio/positions/{userAddress}
/v2/portfolio/positions/{userAddress}/{network}/{vaultId}
/alpha/borrow/aave/position/{network}/{userAddress}
/alpha/borrow/morpho/positions/{network}/{userAddress}
Small details that add up
None of these details is fatal on one protocol. Across ten protocols and twenty chains, they become a permanent engineering surface:
- Cap and liquidity pre-flights
- Oracle reads for USD conversion
- eMode and isolation-mode state
- Parameter changes from governance or risk stewards
- Chain-specific deployment differences
- Approval spender differences
- Withdrawal queues and pending-request state
That is the product layer most teams do not want to own.
Case study 1: Veda BoringVault deposits and withdrawals
Veda is the messy vault example. The curator products built on top of it are attractive yield products, but the integration path is not a simple SDK call.
What a partner has to do today, directly
Per Veda's own integration docs, a deposit into a BoringVault requires:
- Approve the BoringVault contract for the deposit asset.
- Call
teller.deposit(asset, amount, minimumMint)ordepositWithPermitfor EIP-2612 tokens. - Pre-flight
teller.assetData(token).allowDepositsandArcticArchitectureLens.checkUserDeposit()so the deposit does not revert. - Handle the per-vault
shareLockPeriod, during which shares are locked. Wallets have to surface this in the UI. - Read share price from
AccountantWithRateProviders, including handling itspausedstate.
Withdrawals are harder. Depending on the vault, the integrator has to support either teller.withdraw() or the two-step BoringQueue path:
queue.requestOnChainWithdraw(asset, shares, discountBps, deadline).- Wait for the request to mature.
- Track third-party solver fulfillment.
- Index request events and reconcile fulfillment off-chain.
- Handle cancellations through
queue.cancelOnChainWithdraw().
Each vault has its own contract addresses. Liquid USD lives at 0xeDa663610638E6557c27e2f4e973D3393e844E70. Liquid ETH lives elsewhere. eBTC, weETHs, and each new curator vault can have separate Teller, Accountant, and BoringQueue addresses. Veda's docs explicitly note that Teller, Accountant, and Manager are modules designed to be updated or replaced without disrupting core vault contracts. See Veda Architecture and Flow of Funds.
That is the part the user never sees.
The user sees a deposit or withdrawal button. The partner owns the address registry, pre-flight checks, share-lock UI, accountant state, queue state, event reconciliation, and pending-position display.
What changes through vaults.fyi
Through vaults.fyi, the partner asks for transaction context, gets the deposit or withdrawal action, signs through its own wallet, and reads the resulting position and pending state through the same API pattern used across other vaults.
The lens pre-flight, share-lock UX surfacing, accountant pause handling, queue request indexing, solver fulfillment reconciliation, and per-vault address registry sit on our side of the boundary. When Veda rotates a Teller or a new curator vault ships, the partner integration does not need to become a Veda integration project again.
/v2/transactions/context/{userAddress}/{network}/{vaultId}
/v2/transactions/{action}/{userAddress}/{network}/{vaultId}
/v2/portfolio/positions/{userAddress}/{network}/{vaultId}
Case study 2: Borrow on Aave v3
Aave v3 is the familiar example. It has one of the strongest integration surfaces in DeFi. That makes it a better test of the build decision.
The question is not whether a team can call Aave. Many teams can. The question is what the product has to maintain once the Aave integration becomes a real borrow experience.
A major US exchange shared a production borrow spec with us. Their current system pulled from four separate sources:
- Goldsky Aave v3 subgraphs for reserves, user positions, transaction history, parameter history, and utilization history.
- Onchain RPC reads for oracle prices, user balances, collateral flags, health factor, borrow power, interest-rate strategy parameters, and allowances.
- The
@aave/clientpackage for APY history. - Local viem transaction encoding for approve, supply, borrow, repay, withdraw, and collateral-toggle actions.
Those sources fed eleven frontend GraphQL queries.
That is what "just integrate Aave" looks like once the product has to be shippable.
Where the borrow burden actually shows up
The borrow action is only one part of the page. A production borrow product also needs:
- APY history and utilization charts on the market page.
- Parameter and transaction history surfaces.
- Live health factor, LTV, liquidation threshold, and borrow power.
- Per-user collateral status for each asset.
- Allowance and balance checks before action construction.
- A position view that aggregates the user's Aave exposure alongside everything else they hold.
- Equivalent surfaces on each supported network.
The customer spec separated indexed data from real-time reads because the risk surface has to be current. A stale health factor, collateral flag, oracle price, allowance, or borrow-cap value can produce a failed transaction. Worse, stale account data can show a user a borrow action that is no longer safe.
What the Aave product spec required
| Product surface | Direct integration burden | Why it matters |
|---|---|---|
| Market discovery | Subgraph, oracle reads, reserve config, rate-strategy reads | Market tables need prices, rates, liquidity, utilization, caps, and risk parameters |
| User positions | Subgraph plus real-time protocol reads | Balances and collateral flags must be current |
| Borrow capacity | Pool reads plus local calculations | Health factor and borrow power drive warnings and action availability |
| Transaction construction | SDK or local ABI encoding plus allowance checks | The client needs unsigned actions it can review, sign, and broadcast |
| Transaction history | Subgraph plus asset lookups | Users need complete activity records |
| Historical charts | @aave/client plus subgraph history |
APY, utilization, and parameter charts are separate workloads |
| Collateral toggles | Per-user, per-asset state plus transaction construction | Each collateral change has its own user-risk implications |
| Multi-chain support | Backend configuration and chain-specific validation | Every supported network has to be explicitly maintained |
Direct Aave integration fragments the product across indexers, contracts, client libraries, and local transaction builders.
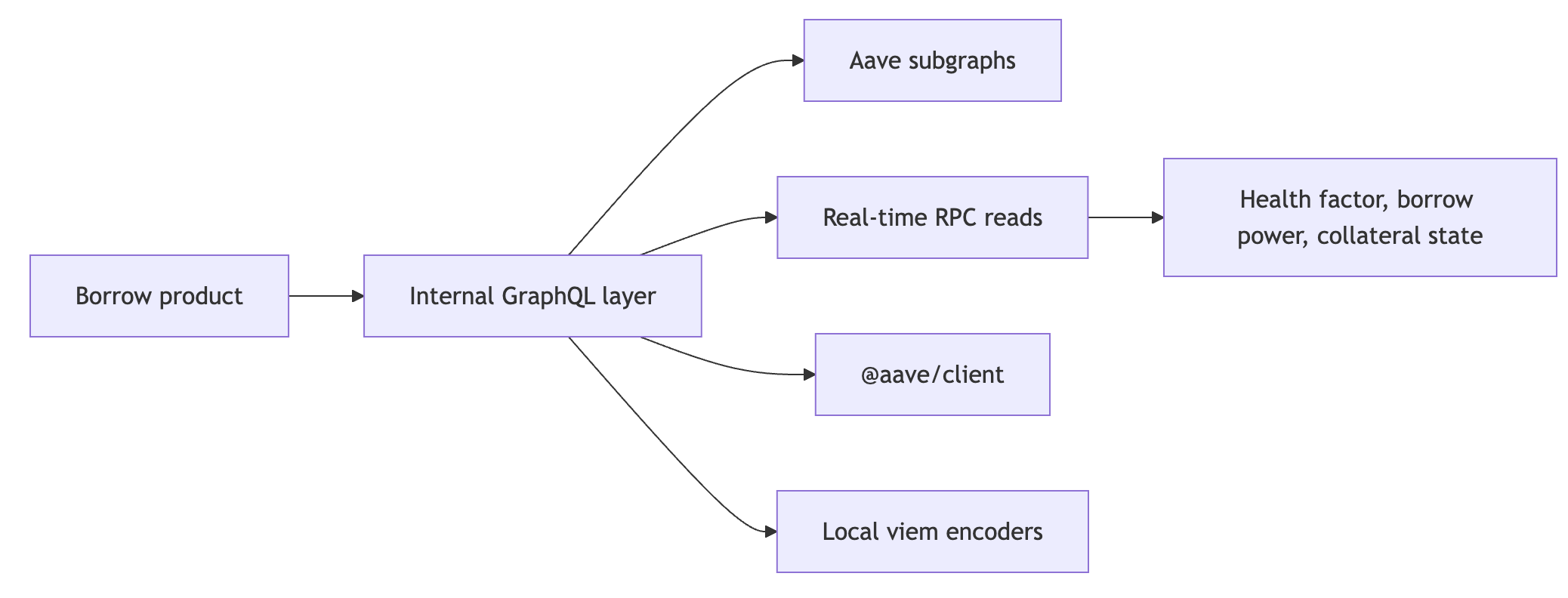
Through vaults.fyi, the product integrates against one API surface:
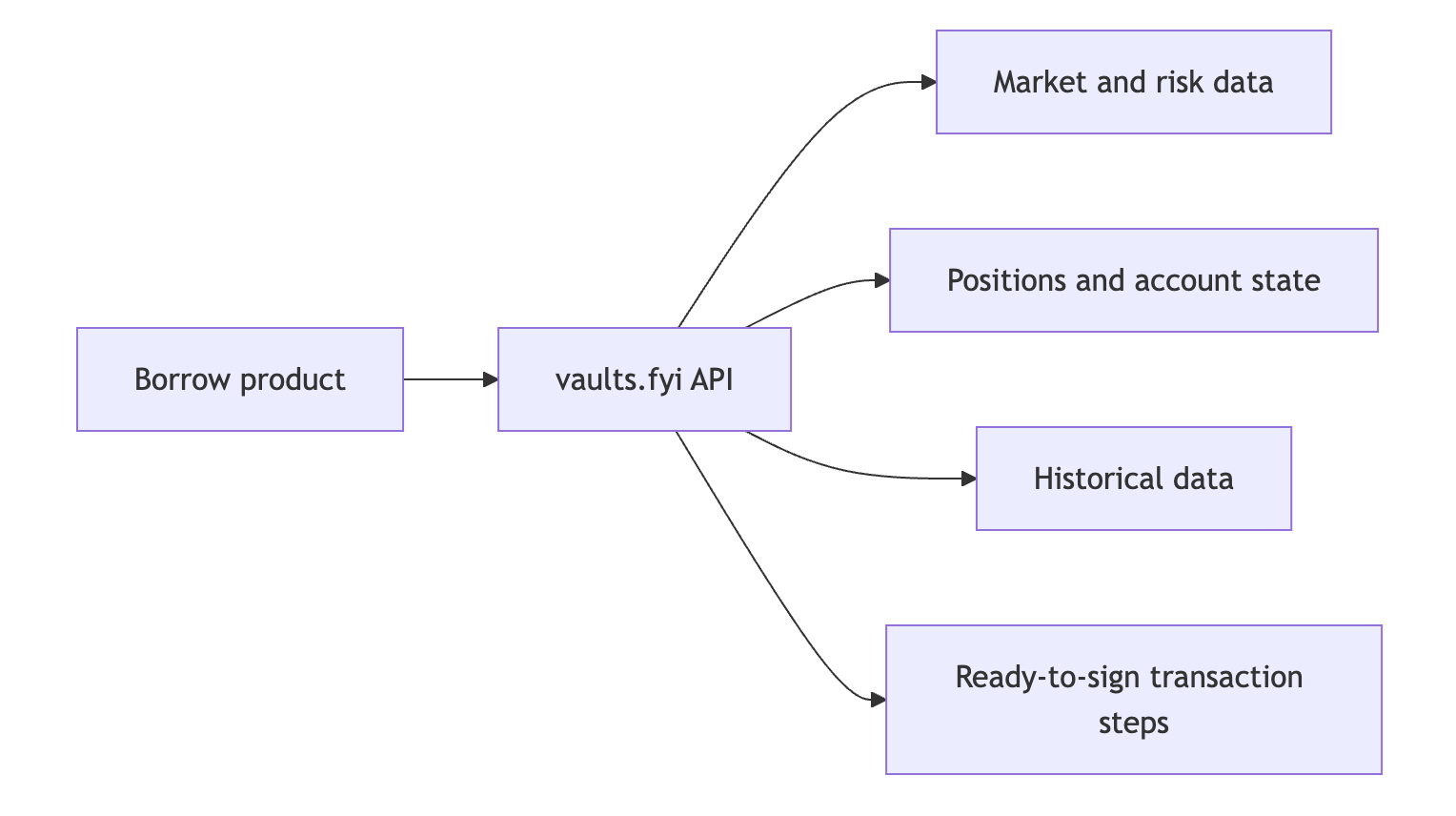
Don't build the backend nobody wants to build
vaults.fyi turns 80+ protocols across 20+ chains into one standard API and SDK.
Non-custodial. End-to-end. From discovery to PnL.



